Decoding an email message
NOVEMBER 1, 2020
Ever wonder how your mail provider knows which emails belong to the same thread?
In the past couple of months that I spent building a customer support software product, I got to work very closely with a technology as ancient as the internet itself - the email.
The engineering problems that I faced were broadly around
- Identifying whether or not an incoming email belongs to an existing email thread.
- Breaking up the email body into two parts - the actual email message and a section of quoted messages consisting of all previous emails in the thread.
- Sending back a reply to the sender in a way that there is a clear distinction between the two parts of the email body mentioned in the previous point.
Each of these challenges are worthy of individual blog posts and therefore I want to first talk about what an email actually looks like to the underlying application that is Gmail.
View the source code of your email
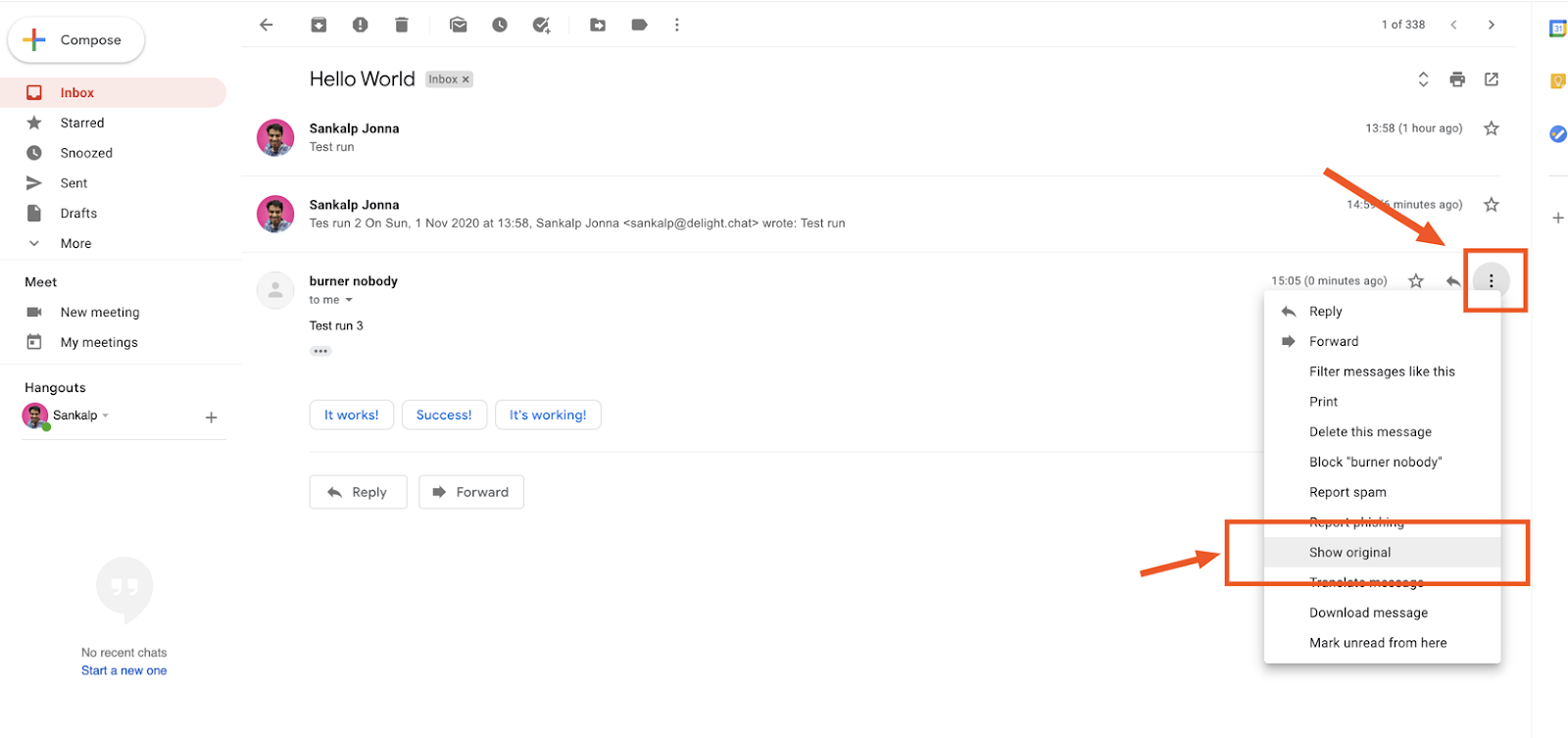
View the original email that Gmail sees
You can navigate to any of your emails in your Gmail inbox and view the original content of an email by clicking on the “show original” option which you will find inside the 3 vertical dots icon.
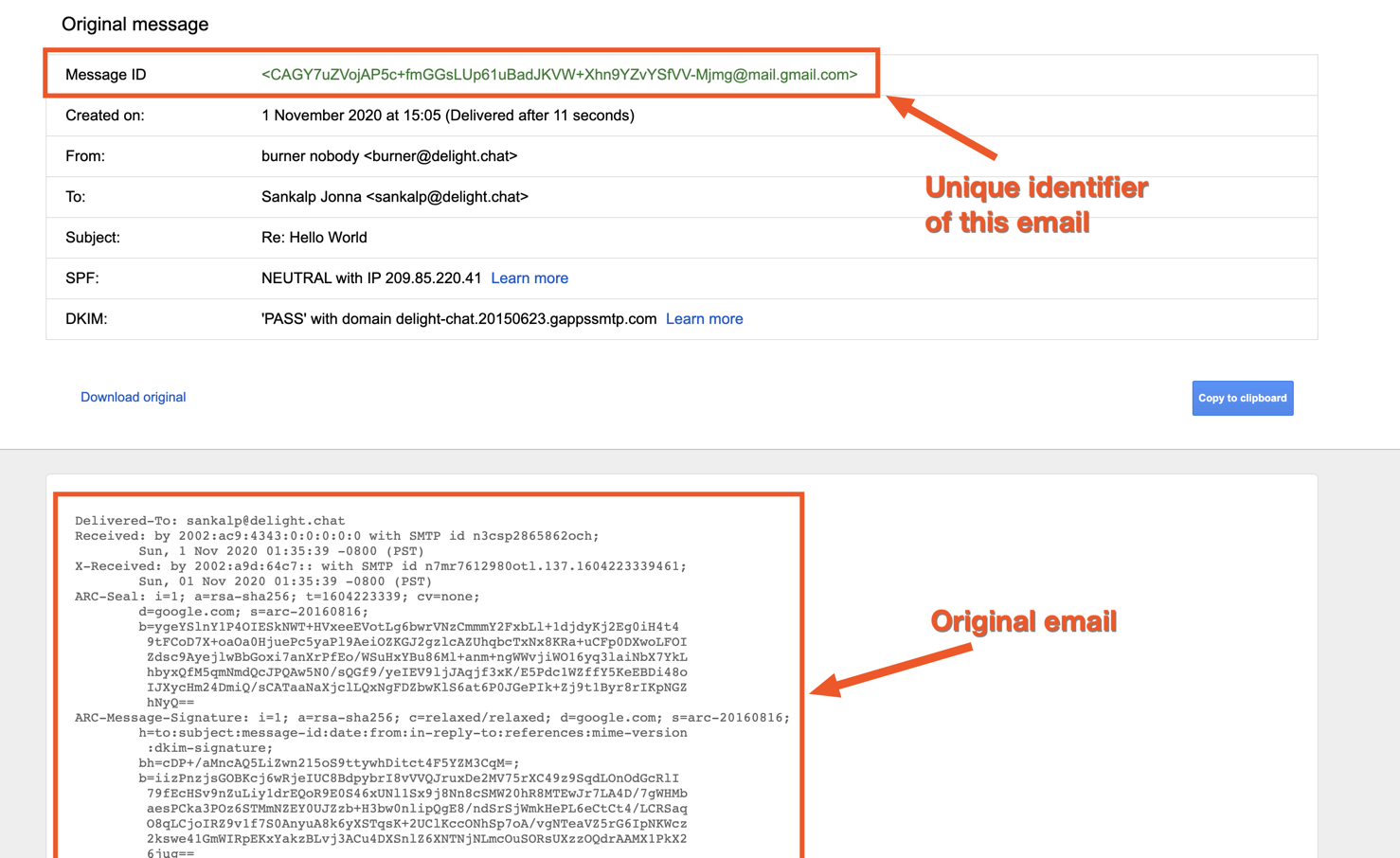
Orignal email
The original email is of the MIME (Multipurpose Internet Mail Extensions) format used by the SMTP (Secure Message Transfer Protocol) to send emails over the internet.
The content of the original email consists of email headers which serve as metadata to this email followed by the actual email which may include plain text, html text, attachments, etc.
Let us examine the headers of this email and see if we can find anything useful.
Useful metadata

Most useful headers from the original email
There were 3 headers that I found to be particularly useful for solving most of the problems described above.
Message-ID
Serves as the unique Identify of this particular email that was assigned by the Gmail server. You can use this as the key to reference a particular email in your database.
In-Reply-To:
This header is the same as the Message-ID of the previous email in the thread to which this email is a reply of. Therefore it can be very handy to create a linked list of emails in your database to establish threading.
References:
If the In-Reply-To header is being used to establish a chain of emails, this chain can be broken even if one link is missing. The References header helps solve this problem by including an array of Message-IDs of all the emails present in this email thread.
Content of the email message

Email body
As mentioned earlier, an email can contain multiple types of content and each of these content blocks are identified by the content-type headers. The most prominent of these content types are the plain text and HTML text which contain the body of the message written by the sender of this email.
It is quite evident that the body of the message contains the entire email thread with all the previous replies whether you look at the plain text or the HTML text.
There appears to be a way for Gmail to identify which part of this message is the actual email and which part can be hidden under the 3 horizontal dots icon used for representing quoted messages of the remaining emails in the thread.
Further examination of plain text

Plain text body and quoted messages of past emails
It appears that every quoted email is preceded by a timestamp of the message followed by the sender of the message.
This leads to the possibility that emails clients use a regex to identify the occurrence of this pattern in the email and use that to make a distinction between the email and quoted messages of previous emails. This is the solution that we are currently exploring at delightchat.io and the results have so far been promising.
Closing notes
There are several other email headers which are specific to the email provider and each provider follows their own convention of handling quoted emails. There are also instances where some of the headers mentioned above might be entirely missing.
After spending a lot of time exploring the nuances of many different email providers, it is pretty clear that it is going to be hard to build a catch all solution from day one. Instead, we have adopted a sort of an incremental solution which we keep building on top of as we find new edge cases.