Handling more than 200 transactions per second using python-rq
JULY 26, 2020
A common use case for any software product is the ability to run a certain business logic whenever a particular event gets triggered. This event could occur in the form of a webhook fired by a 3rd party service to your server or it could be generated via your product itself. The point being this event triggers a transaction in your system and the loss of even a single transaction is not acceptable.
This seems straightforward enough when dealing with a low rate of such events, but if your server receives these events at the rate of 200 requests per second and each of these events require significant resources for processing them, it is no longer a trivial thing to do.
We had a similar requirement while building our product which is a tool that helps e-commerce merchants notify their customers when orders are confirmed/shipped via WhatsApp. To implement this we register webhooks to receive order lifecycle events whenever a new e-commerce store signs up with our product.
This did not seem like a big deal at first until we released that if we acquire even a handful of stores that have a very high volume of orders, the number of webhooks we will receive is going to increase exponentially and if we need the product to scale, we would have to queue up the events and process them asynchronously instead of processing it the moment we receive a webhook.
Expectations from a message queue system
There are 4 primary things that are needed if you want to queue up messages and process them asynchronously.
- Monitoring: A dashboard where you can view all the current asynchronous jobs and make sure all of them are running smoothly and there is no clog anywhere.
- Error handling: The ability to retry failed transactions without having to receive the event again.
- Zero loss: None of the events must be lost and must stay in the queue until they are picked up.
- Scalability: If the volume of messages goes up, handling them should be as simple as adding another worker to the pool.
Available methods for doing this
The above mentioned problem is not something new and has already been solved in many ways. Here are a few that I am aware of.
- AWS SQS as the queue and AWS Lambda as the handler for the jobs in the queue.
- Celery is a great framework that solves exactly this and it has compatibility with AWS SQS, Redis and Rabbit MQ.
- Python-rq with Redis as the queue.
I immediately ruled out the first method because it would involve too much vendor lock in with AWS and out of the remaining 2 methods, I personally got a little bit spooked by Celerys documentation as it seems a bit overwhelming for my simple use case of being able to deploy worker programs that pick up items from a queue and process them.
Therefore I decided to go with python-rq as it was something I had previously tinkered with, so let's go through each of the expectations that I listed earlier and see if python-rq satisfied all of them.
Monitoring
To quote one of the lines from the python-rq documentation, “Monitoring is where RQ shines”. You get access to a dashboard where you can view jobs that are currently being processed, pending jobs and failed jobs.
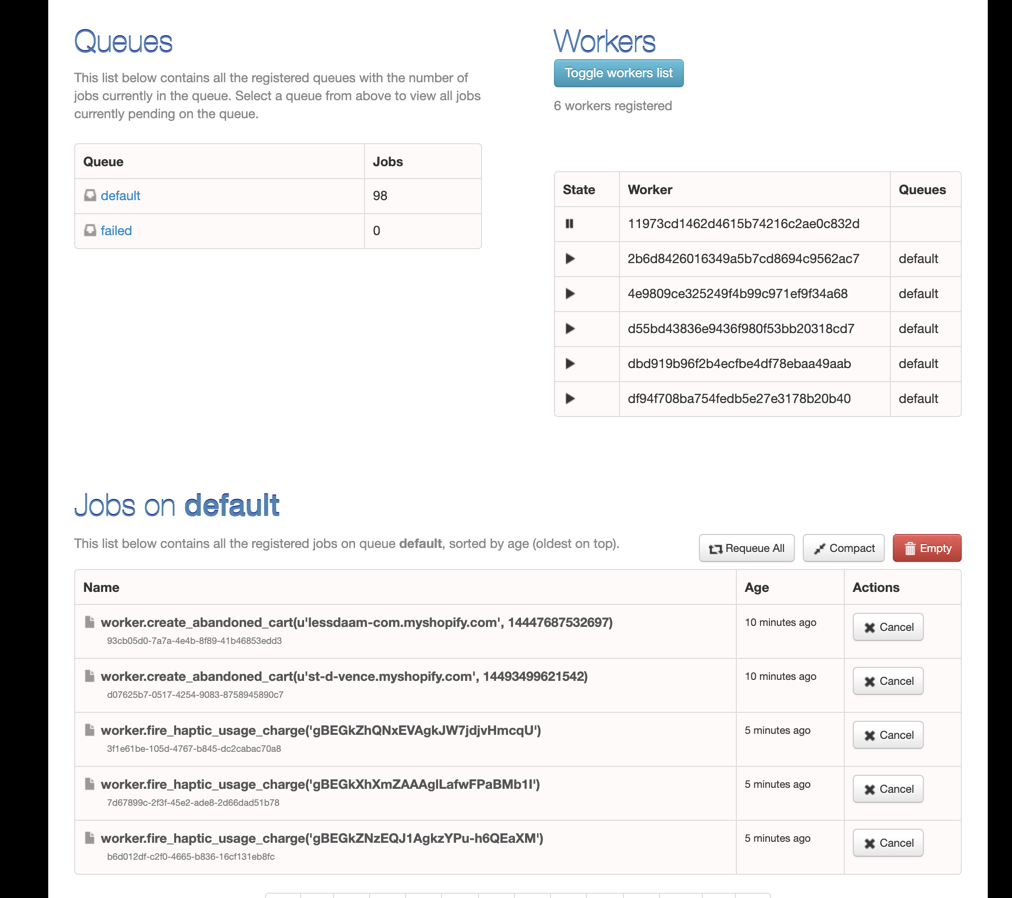
RQ dashboard for viewing status of jobs
If you do not specify any queue while deploying the service, there is one queue created called “default” and all the jobs you enqueue will go into this queue.
Alternatively you can define as many queues as you want, and put jobs into the respective queues based on their priority. All of this is very well documented.
If you need to monitor some more things like how many jobs are queued at a given time in the form of a time series database or the maximum queued jobs within a given time range, you could export these metrics using rq_exporter and display them on a grafana dashboard.
Error handling
Python-RQ has several ways to retry failed jobs, you could specify a retry count while enqueuing the job itself as mentioned in their documentation.
You could also specify a time interval between each retry if you don’t want the job to be retried immediately.
Lastly you can also specify different time delays between each retry and achieve a system where if a job fails, you retry after 10 minutes and if it fails again, you could retry after 20 minutes, etc.
Even if you don’t specify any retry count, there is a default safety net built in where the failed jobs go into a “failed” queue and the same is displayed on the dashboard. You can retry them manually by clicking on “Requeue”.
You can even see the stack trace of the failed job so that you can make changes to the code if required before retrying the job.
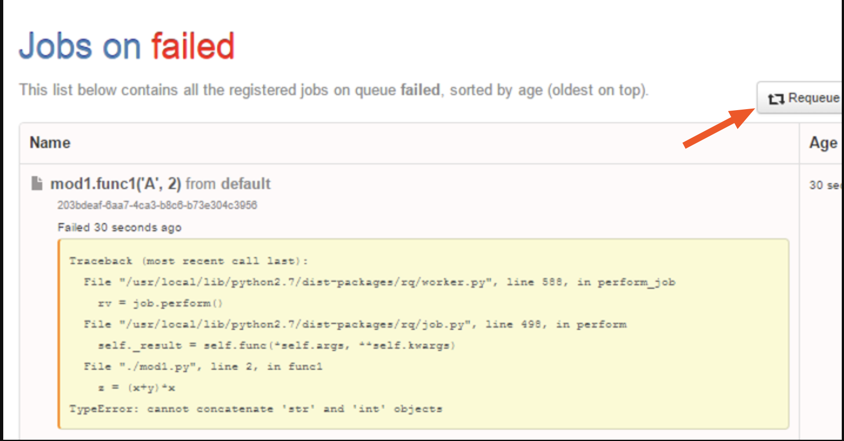
Failed jobs displayed on RQ dashboard
Python-rq also allows you to define a custom exception handler at the time of starting your workers which you can use to do stuff like sending an alert to yourself over email/slack whenever there is an exception.
Zero loss
When you restart python-rq it does a warm shutdown where new jobs from the queue are no longer accepted and existing jobs will finish running completely before shutting down the service. This ensures that there is no loss in data.
The producer program which is responsible for enqueuing the jobs must make sure that as soon as an event is received, it is immediately enqueued before running any other logic and this will ensure that there is no loss due to the producer failing to enqueue a job in time.
Since all the jobs will be saved in the Redis database and Redis has its own methods for prevention of data loss, this pretty much ensures that all your transactions will be executed.
Scalability
The Beauty of this setup is that if your application scales and you start receiving too many events, the server responsible for enqueuing the events will not face any lag and the only implication of this is that there might be a lag between the time a job is enqueued and the time it is executed.
If you need to reduce this lag, all you have to do is deploy another RQ worker that listens on the same Redis queue and the tasks will automatically get shared between all the existing workers that are subscribed to that queue. Based on how your traffic scales, you can keep deploying new workers on new instances without having to change anything else.
Scheduling tasks with python-rq
An added advantage of this infrastructure is that it also takes care of the case where one has to schedule a task to be executed at a later time. There are of course many ways of achieving this including cron jobs, but having this ability within your queuing infrastructure is very handy because all the other aspects like error handling and monitoring automatically get applied to this as well.
To add job scheduling abilities to python-rq, you would have to install rq-scheduler and run it as a separate service. This service will take care of picking up jobs that are to be executed at a given point in time and enqueue them into the queue that python-rq listens on.
Closing notes
For our particular use case, we receive close to 200 transactions per second and because they all go straight into a queue, 99% of these requests have a response time of 25 milliseconds or less.
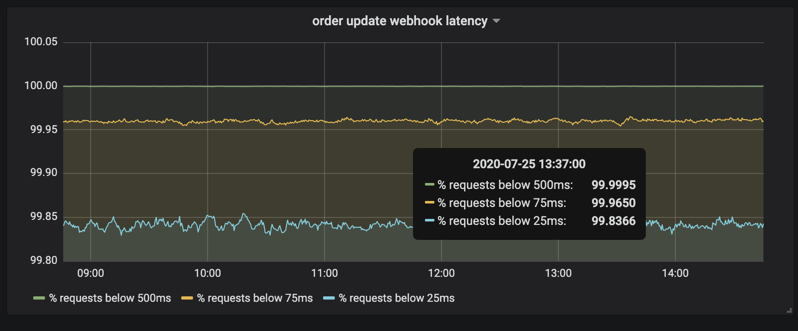
Server response time for enqueing jobs
As for the performance of the workers, we have currently deployed 5 workers and their capacity based on their free time vs busy time looks something like this.
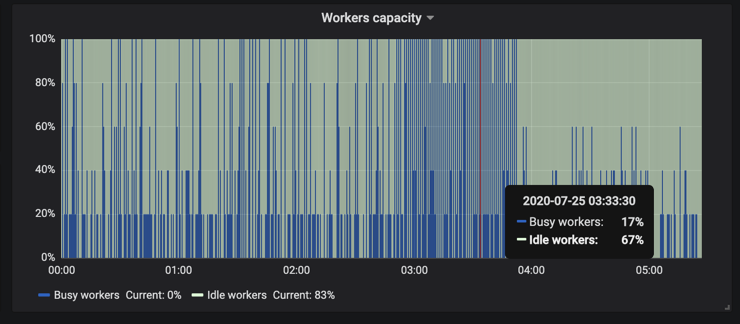
RQ worker capacity
The blue shade represents workers being busy and the rest of the time workers are free. In terms of how many jobs are queued up at any given point of time, the maximum jobs queued at a given moment is around 200.
But it is quite clear that during certain times of the day, the workers are used quite a bit while the rest of the time they are free.
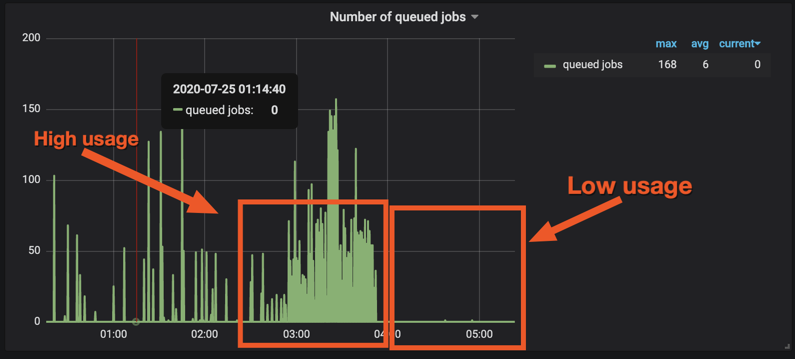
Jobs queued up at any given point in time
In terms of cost of running this set up, we have one AWS Lightsail instance that is responsible for receiving all the webhooks and enqueuing all the jobs that costs 20$ per month and we have another instance where we run Redis and all the 5 RQ workers which costs 40$ a month, so in total we spend 60$ a month to handle 200 transactions per second.